Clustering Analysis이란?
- 여러 집단의 데이터들이 섞여 있고 각 데이터의 소속집단을 모르는 경우 유사한 속성을 갖는 데이터의 군집을 찾는 기법
- 주어진 개체 중에서 유사한 것들을 몇몇의 집단으로 그룹화하여, 각 집단의 성격을 파악함으로써 데이터 전체의 구조에 대한 이해를 돕고자 하는 탐색적 데이터 분석 방법
목적
* 주어진 데이터를 통해 군집을 잘 구분하는 것이 분석의 최대 목적
- 동일한 군집의 개체들은 유사한 성격을 갖도록한다.
- 서로 다른 군집에 속한 개체들 사이에는 상대적으로 서로 다른 성격을 갖도록한다.
유사성과 거리.
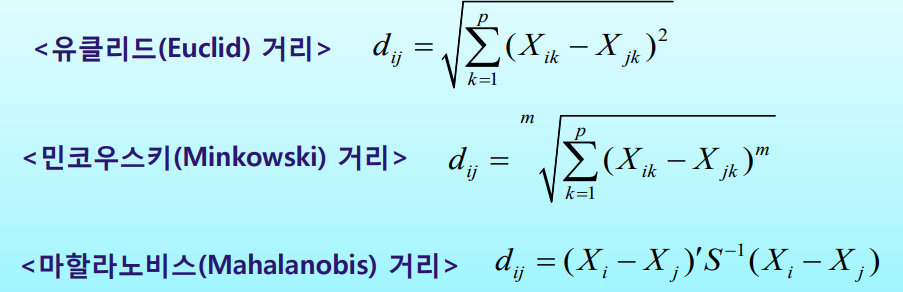
군집분석에서는 유사성의 척도로 거리를 사용한다
거리의 종류는 크게 세 가지로 유크리드 거리, 민코우스키 거리, 마할라노비스 거리가 있고 통상적으로 유클리드 거리를 많이 사용한다. 또한 유클리드 거리를 구하기 전 일반적으로 변수들을 정규화 또는 표준화를 해야한다.
그 이유는 각 변수의 단위크기에 영향을 받을 수 있기 때문이다.
Clustering Analysis method
- Hierarchical method ex) Single-linkage algorithm, Complete-linkage algorithm
- Partitoning method ex) K – means algorithm
-Density - based method ex) DBSCAN
K-means algorithm(Clustering)

주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로 k는 분석가가 임의로 정하여 진행됩니다.
k를 정하는 기준은 크게 두 가지가 있습니다.
- elbow method
가장 보편적으로 이용되는 방법으로 클러스터 내의 총 변동을 설명하는 WCSS(Within Clusters Sum of Squares)를 이용해 WCSS값과 클러스터 K 갯수에 대한 커브선을 그려 뾰족하게 구부러진 부분이나 특정 지점이 팔처럼 굽어지는 부분을 K로 지정하는 방법
- 실루엣 스코어
실루엣 스코어은 개체가 다른 클러스터(seperation)에 비해 자신의 클러스터(cohesion)와 얼마나 유사한 지 측정합니다. 실루엣 범위는 -1에서 +1까지이며, 값이 높으면 객체가 자체 클러스터와 잘 일치하고 인접 클러스터와 잘 일치하지 않음을 나타냅니다. 실루엣 스코어는 전체 시루엣 스코어의 평균과 각 크러스터별 스코어의 평균이 비슷하도록 k를 설정합니다.
k값이 선택됐으면 k-means clustering은 다음과 같은 절차로 군집을 생성합니다.
1. 초기군집의 형성
- 각 개체들에 대하여 군집 초기값들과의 거리를 계산
- 거리가 가장 가까운 초기값에 개체들을 할당
- 군집의 중심 계산(mean 값을 사용)
2, 개체들의 재할당
- 각 개체들을 가장 가까운 군집중심에 재할당하고 군집의 중심을 계산
- 군집중심들의 변화가 일정 수준 이하가 될 때까지 반복
- 반복이 완료되면 최종 군집 형성
즉 k-means clustering은 전체 데이터를 k만큼 나누고 mean값으로 중심을 설정해 가장 적절하게 cluster를 형성하는 알고리즘이다.
'머신러닝' 카테고리의 다른 글
| [머신러닝][앙상블/배깅][개념] 랜덤포레스트(Random Forest) (0) | 2022.01.20 |
|---|---|
| [머신러닝][파이썬]의사결정나무(DecisionTreeRegressor) (2) | 2022.01.19 |
| [머신러닝][파이썬] 의사결정나무(DecisionTreeClassifier) (2) | 2022.01.17 |
| [머신러닝][개념]의사결정나무 (0) | 2022.01.15 |
| [머신러닝][파이썬]K-means clustering (0) | 2022.01.14 |




댓글