오늘은 캐글의 CarPrice_Assignment data를 가지고 회귀트리(DecisionTreeRegressor)를 구현해보겠습니다.
1. 모듈 및 데이터 불러오기
|
1
2
3
4
5
6
7
8
9
|
import pandas as pd
import numpy as np
from pydotplus import graph_from_dot_data
from sklearn.tree import export_graphviz
from IPython.display import Image # CART Tree 그림
import pydotplus
import os
df= pd.read_csv("CarPrice_Assignment.csv")
|
cs |
기본적으로 pandas, numpy 와 모델 시각화를 위한 모듈만 불러오고 시작했습니다.
데이터를 불러올 때는 pd.read_csv()로 불러오면 됩니다.
참고로 데이터를 불러올때 데이터가 있는 경로와 내가 불러오는 경로가 같다면 데이터의 경로를 지정하지 않고
"데이터.csv"만으로 불러올 수 있습니다.
2. 원-핫 인코딩 및 데이터 분리
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# 필요없는 변수 제거
data=df.drop(["car_ID","CarName"],axis=1)
# Features와 target 나누기
t_features = data[data.columns[:-1]]
t_target = data[data.columns[-1]]
# 더미변수 생성(원핫인코딩)
t_features = pd.get_dummies(data = t_features, columns = ['symboling'], prefix = 'symboling')
t_features = pd.get_dummies(data = t_features, columns = ['fueltype'], prefix = 'fueltype')
t_features = pd.get_dummies(data = t_features, columns = ['aspiration'], prefix = 'aspiration')
t_features = pd.get_dummies(data = t_features, columns = ['doornumber'], prefix = 'doornumber')
t_features = pd.get_dummies(data = t_features, columns = ['carbody'], prefix = 'carbody')
t_features = pd.get_dummies(data = t_features, columns = ['drivewheel'], prefix = 'drivewheel')
t_features = pd.get_dummies(data = t_features, columns = ['enginelocation'], prefix = 'enginelocation')
t_features = pd.get_dummies(data = t_features, columns = ['enginetype'], prefix = 'enginetype')
t_features = pd.get_dummies(data = t_features, columns = ['cylindernumber'], prefix = 'cylindernumber')
t_features = pd.get_dummies(data = t_features, columns = ['fuelsystem'], prefix = 'fuelsystem')
# Train/Test 분리
from sklearn.model_selection import train_test_split
train_features, test_features , train_target, test_target = train_test_split(
t_features, t_target, test_size = 0.2, random_state = 2021)
print(len(train_features))
print(len(train_target))
print(len(test_features))
print(len(test_target))
|
cs |
먼저 분석에 필요없는 변수들은 제거한 후 독립변수와 종속변수를 분리했습니다.
그리고 범주형변수의 경우 더미변수를 만들어줬는데 사실 의사결정나무는 이런 더미변수를 만드는 작업은 필요없습니다.
따라서 더미변수를 만드는 과정은 생략해도 무방합니다.
모델의 학습을 위해 Train/Test를 분리했습니다.
3. train/validation 커브 측정
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
# 회귀트리 파이프라인 생성
from sklearn.pipeline import make_pipeline
pipe_tree = make_pipeline(DecisionTreeRegressor(random_state=2021))
# 트리의 파라미터 키값 확인
pipe_tree.get_params().keys()
# validation curve 측정
from sklearn.model_selection import validation_curve
import numpy as np
param_range = [1,2,3,4,5,6,7,8,9,10] # max_depth 범위 설정
train_scores, validation_scores = validation_curve(estimator = pipe_tree, #기본모형 선택
X = train_features,
y = train_target,
param_name = 'decisiontreeregressor__max_depth', #pipe_tree.get_params().keys()에서
param_range=param_range,
scoring= "neg_mean_squared_error",
cv=10)
train_mean = (np.mean(-train_scores, axis = 1))
train_std = np.std(-train_scores, axis = 1)
validation_mean = np.mean(-validation_scores, axis = 1)
validation_std = np.std(-validation_scores, axis = 1)
plt.plot(param_range, train_mean,
color='blue', marker='o',
markersize=5, label='training MSE')
plt.fill_between(param_range,
train_mean + train_std,
train_mean - train_std,
alpha=0.15,
color='blue')
plt.plot(param_range, validation_mean,
color='green', linestyle='--',
marker='s', markersize=5,
label='validation MSE')
plt.fill_between(param_range,
validation_mean + validation_std,
validation_mean - validation_std,
alpha=0.15, color='green')
plt.grid()
plt.xlabel('Number of max_depth')
plt.legend(loc='lower right')
plt.xlabel('Parameter max_depth')
plt.ylabel('MSE')
plt.ylim([30000.00, 50000000.00]) # 보고싶은 구간 설정
plt.tight_layout()
plt.show()
|
cs |
파라미터 조절을 하는 또 하나의 방법은 validation curve가 있습니다.
위 코드는 max_depth : 트리의 깊이에 따라 Train/validation score를 보는 것입니다. 두 score의 차이가 커지면 과적합이 되는 것입니다. 즉 과적합을 방지하기 위해 적절한 파라미터 범위를 찾는 것입니다.
4. 파라미터 최적화(GridSearchCV)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
from sklearn.model_selection import GridSearchCV
# parameter선택은 pipe_tree.get_params().keys() 에서 고르기.
param_range1 = [1,2,3,4,5,6,7,8,9,10]
param_range2 = [10, 20, 30, 40, 50]
param_range3 = ['mse', 'mae'] # 'explained_variance'도 가능
param_grid = [{'decisiontreeregressor__max_depth': param_range1,
'decisiontreeregressor__min_samples_leaf': param_range2,
'decisiontreeregressor__criterion': param_range3}]
gs = GridSearchCV(estimator = pipe_tree,
param_grid = param_grid, # 찾고자하는 파라미터. dictionary 형식
scoring = 'neg_mean_squared_error', # Regression 일때 'neg_mean_squared_error','r2' 등
cv=10,
n_jobs= -1) # 병렬 처리갯수? -1은 전부를 의미
gs = gs.fit(train_features, train_target)
print(-gs.best_score_)
print(gs.best_params_)
|
cs |
오버피팅을 방지할 수 있는 적절한 파라미터 범위를 찾았다면 GridSearchCV를 통해 파라미터를 최적화하면 됩니다.
여기서 주목할 점은 scoring = 'neg_mean_squared_error' 입니다.
neg, 즉 음수값을 취하는 것입니다. 통상적으로 mean_squared_error는 낮아지는게 좋습니다. 하지만 여기에 마이너스를 붙이면 커질 수록 좋은 것이겠죠. GridSearchCV는 soring == 점수 라고 생각하기 때문에 값이 커지도록 파라미터를 조절합니다. 따라서 mse값에 음수를 취하는 것입니다.
5. 모델 학습 및 test predict
|
1
2
3
4
5
6
7
|
best_tree = gs.best_estimator_ # 최적의 파라미터로 모델 생성
best_tree.fit(train_features, train_target)
best_tree_for_graph = DecisionTreeRegressor(criterion='mse', max_depth=3, min_samples_leaf=10, random_state = 2021)
best_tree_for_graph.fit(train_features, train_target)
y_pred = best_tree.predict(test_features)
|
cs |
파라미터를 최적화한 후 모델을 학습시키고 test의 예측값을 도출합니다.
여기서 모델을 두 개를 만드는 이유는 best_tree_for_graph 라는 명칭에서 알 수 있듯이, 모델 시각화를 위한 모델입니다. 이렇게 하는 이유는 파이프라인 모델은 모델 시각화가 안되기 때문입니다.
6. 모델 성능 평가
|
1
2
3
4
5
6
7
8
9
10
|
from sklearn.metrics import mean_squared_error, mean_absolute_error
mse=mean_squared_error(test_target,y_pred)
print('MSE: %.3f' % mean_squared_error(test_target,y_pred))
print('MAE: %.3f' % mean_absolute_error(test_target,y_pred))
print('RMSE: %.3f' % np.sqrt(mse))
def MAPE(y_test, y_pred):
return np.mean(np.abs((y_test - y_pred) / y_test)) * 100
print('MAPE: %.3f' % MAPE(y_test, y_pred))
|
회귀 모델의 성능 평가는 대표적으로 MSE, MAE, RMSE, MAPE 등이 있습니다.
모두 다른 것 같지만 목적은 모두 같습니다. 실제값과 예측값의 차이가 얼마나 되는 지를 나타내주는 지표이며
절대값을 쓰냐, 제곱을 하느냐, 루트를 씌우느냐 , 백분율로 표현하는 등의 차이만 있을 뿐입니다.
MSE = (실제 - 예측)^2 / n
MAE = |실제 - 예측| / n
RMSE = 루트(MSE)
MAPE =(|실제 - 예측/ 실제|/n )* 100
여기서 차이점은 MAPE이고 이는 정규화를 해주기 때문에 이상치값에 상관없이 모델을 평가하는 것입니다.
그래서 저는 통상적으로 RMSE와 MAPE 두 지표를 많이 사용합니다.
7. 변수중요도 및 모델 규칙 시각화
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
import numpy as np
feature_names = train_features.columns.tolist()
target_name = np.array(['price'])
from pydotplus import graph_from_dot_data
from sklearn.tree import export_graphviz
from IPython.display import Image # CART Tree 그림
import pydotplus
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
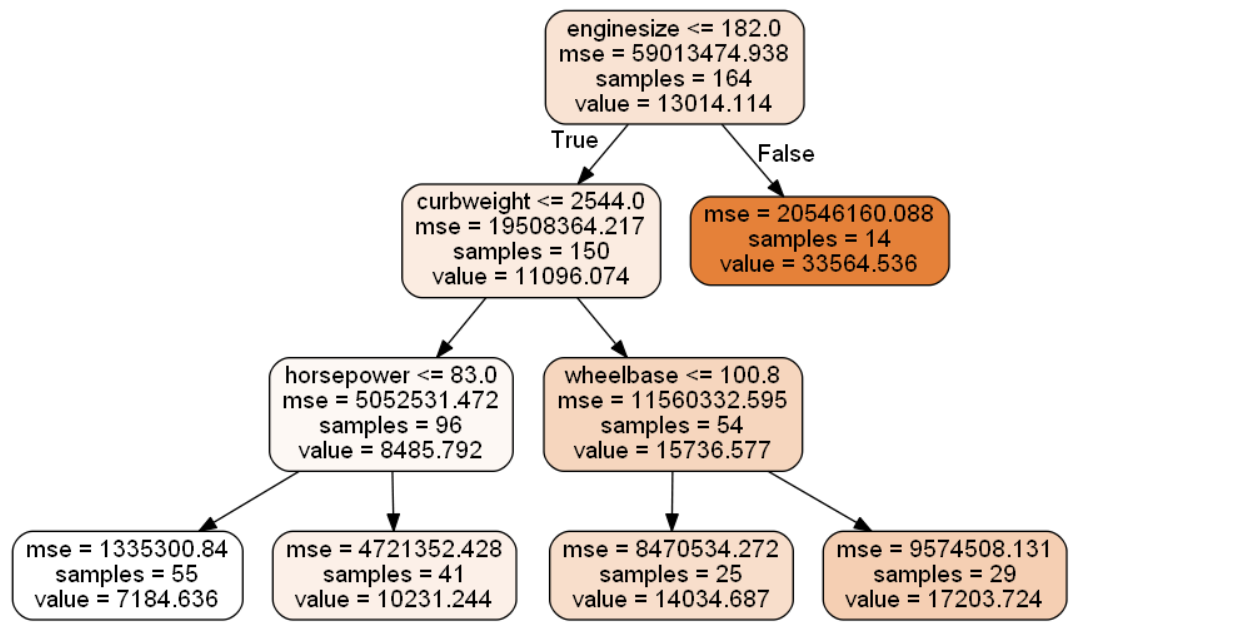
dot_data_best = export_graphviz(best_tree_for_graph,
filled = True,
rounded = True,
class_names = target_name,
feature_names = feature_names,
out_file = None)
graph_best = graph_from_dot_data(dot_data_best)
graph_best.write_png('tree_best_regression.png') #Tree 이미지를 저장
dt_graph_best = pydotplus.graph_from_dot_data(dot_data_best)
Image(dt_graph_best.create_png())
# Feature Importance
import seaborn as sns
feature_importance_values = best_tree_for_graph.feature_importances_
# Top 중요도로 정렬하고, 쉽게 시각화하기 위해 Series 변환
feature_importances = pd.Series(feature_importance_values, index=train_features.columns)
# 중요도값 순으로 Series를 정렬
feature_top5 = feature_importances.sort_values(ascending=False)[:5] # 10개 혹은 20개 등 개수를 바꾸고 싶다면 이 부분을 변경
plt.figure(figsize=[8, 6])
plt.title('Feature Importances Top 5')
sns.barplot(x=feature_top5, y=feature_top5.index)
plt.show()
|
cs |
마지막은 모델과 변수중요도를 시각화하는 코드입니다.
25번째줄부터 변수중요도를 구하는 코드이며, 여기서는 가장 영향력있는 변수 5개를 보았지만 10개 혹은 20개 등으로 변경할 수 있습니다.
'머신러닝' 카테고리의 다른 글
| [머신러닝][파이썬] Random Forest Classifier(분류) (0) | 2022.01.25 |
|---|---|
| [머신러닝][앙상블/배깅][개념] 랜덤포레스트(Random Forest) (0) | 2022.01.20 |
| [머신러닝][파이썬] 의사결정나무(DecisionTreeClassifier) (2) | 2022.01.17 |
| [머신러닝][개념]의사결정나무 (0) | 2022.01.15 |
| [머신러닝][파이썬]K-means clustering (0) | 2022.01.14 |




댓글